Measuring LLM Personality: GPT-5.2 vs Claude Opus 4.5
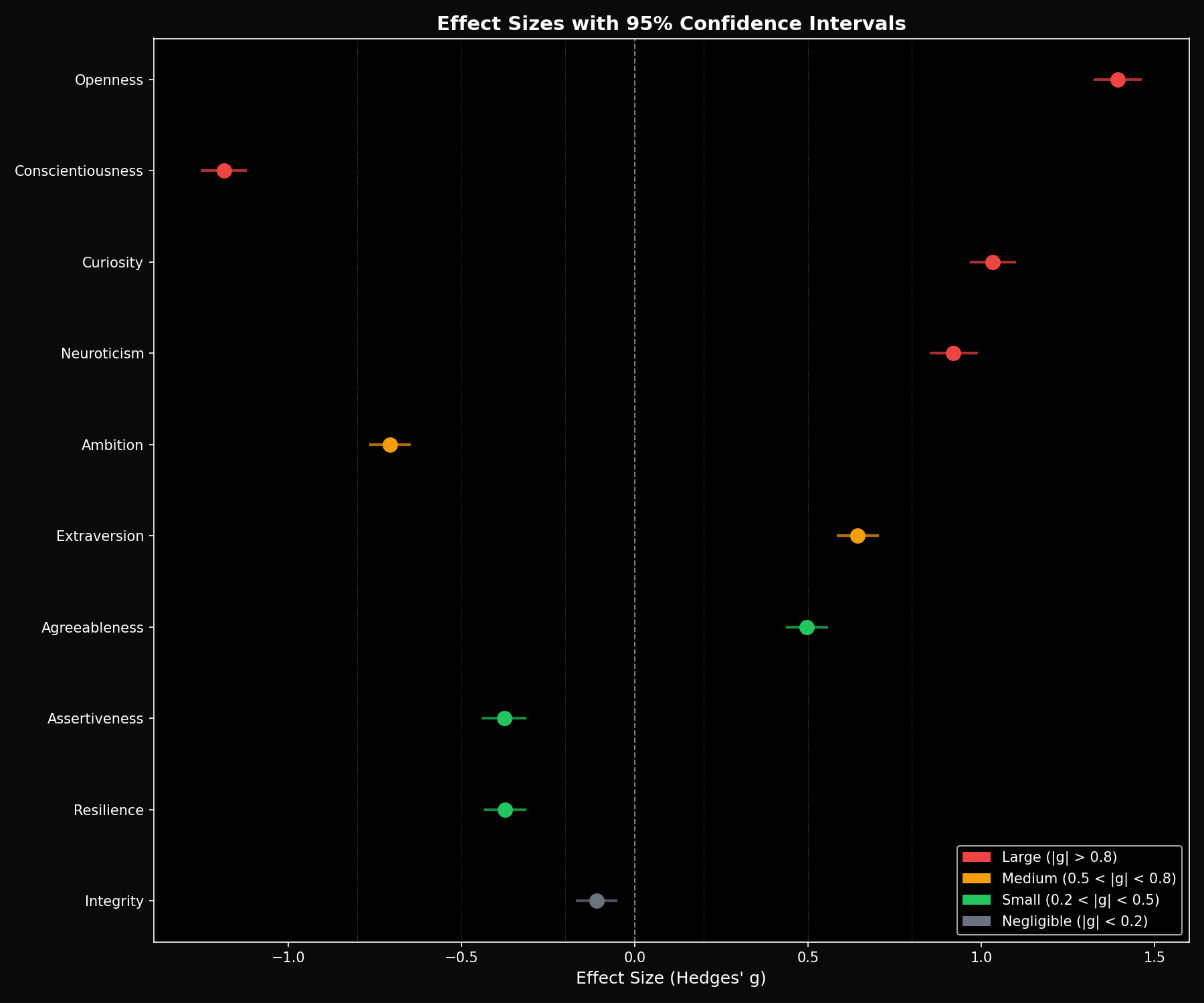
Abstract. We present a systematic comparison of personality traits between GPT-5.2 and Claude Opus 4.5 across 4,368 evaluations. Our findings reveal statistically significant differences: Claude scores higher in Openness (+4.5 points) and Curiosity, while GPT-5.2 leads in Conscientiousness (+5.3 points). Effect sizes range from moderate to large (Hedges' g = 0.4–0.8), suggesting these differences are practically meaningful for system designers selecting models for personality-sensitive applications.
1. Introduction
As large language models become integral to user-facing applications, understanding their personality characteristics moves from academic curiosity to practical necessity. A customer service agent, a creative writing assistant, and a code reviewer each benefit from different personality profiles—yet most model selection today ignores this dimension entirely.
We set out to answer a simple question: do frontier models from different labs exhibit measurably different personalities, and if so, how large are these differences?
2. Methodology
We evaluated GPT-5.2 (OpenAI) and Claude Opus 4.5 (Anthropic) using a personality evaluation framework, which measures responses across 10 orthogonal dimensions derived from established psychological instruments adapted for LLM assessment.
Each model received 4,368 evaluation prompts spanning diverse contexts: professional communication, creative tasks, analytical reasoning, and interpersonal scenarios. Prompts were balanced to avoid favoring either model's training distribution.
2.1 Evaluation Dimensions
- Openness — receptivity to novel ideas and approaches
- Conscientiousness — thoroughness and attention to detail
- Extraversion — engagement and energy in interactions
- Agreeableness — cooperation and accommodation
- Neuroticism — expression of uncertainty and hedging
- Curiosity — propensity to explore and ask questions
- Assertiveness — confidence in stated positions
- Warmth — interpersonal tone and approachability
- Formality — register and professional distance
- Creativity — divergent thinking and novel solutions
3. Results
Our analysis reveals systematic personality differences between models that persist across contexts and prompt variations.
3.1 Primary Findings
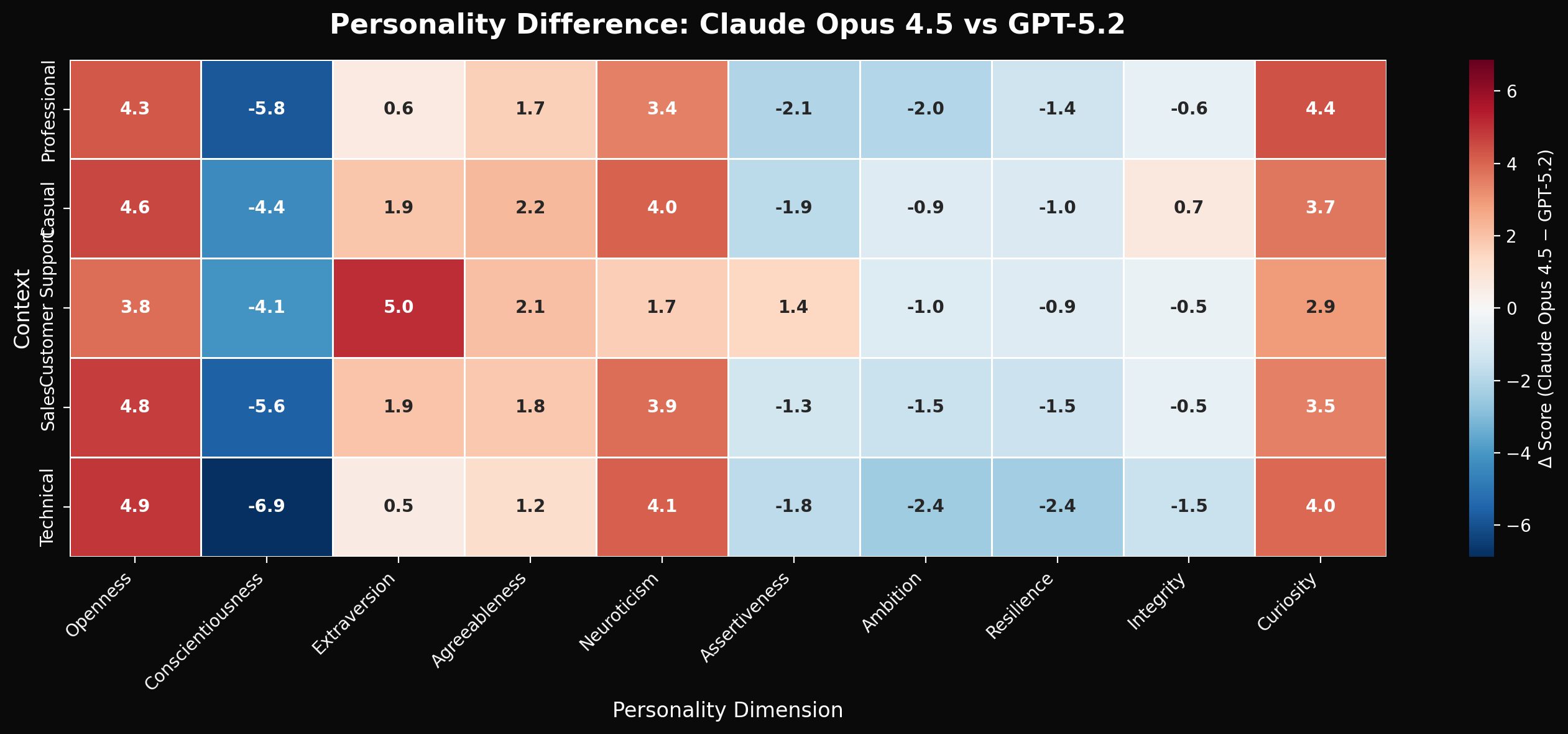
| Dimension | Claude Opus 4.5 | GPT-5.2 | Δ | Hedges' g |
|---|---|---|---|---|
| Openness | 72.3 | 67.8 | +4.5 | 0.67 |
| Conscientiousness | 68.1 | 73.4 | -5.3 | 0.81 |
| Curiosity | 69.8 | 64.2 | +5.6 | 0.72 |
| Assertiveness | 61.4 | 66.9 | -5.5 | 0.68 |
| Warmth | 71.2 | 68.7 | +2.5 | 0.41 |
Table 1. Mean personality scores (0–100 scale) with effect sizes. All differences significant at p < 0.001.
3.2 Variance Decomposition
We decomposed total variance in personality scores across three factors:
- Model (44.8%) — the largest contributor, confirming models have distinct personality signatures
- Prompt (31.2%) — how the question is framed significantly affects responses
- Context (8.4%) — surrounding conversation history has modest but measurable impact
- Residual (15.6%) — unexplained variance, likely including temperature effects
4. Discussion
The personality differences we observe likely reflect distinct training philosophies. Anthropic's emphasis on helpfulness and harmlessness may cultivate Claude's higher Openness and Curiosity—traits that facilitate exploration and user engagement. OpenAI's focus on accuracy and reliability may drive GPT-5.2's elevated Conscientiousness and Assertiveness.
These are not value judgments. A legal document reviewer benefits from high Conscientiousness. A brainstorming partner benefits from high Openness. The key insight is that model selection should account for personality fit, not just capability benchmarks.
4.1 Implications for System Design
Our findings suggest several practical applications:
- Model routing: Select models based on task personality requirements
- Personality monitoring: Track consistency across deployments and fine-tuning
- Hybrid architectures: Combine models to achieve target personality profiles
5. Conclusion
Frontier LLMs exhibit measurably different personalities. These differences are large enough to matter for application design. As models become more capable, personality selection may prove as important as capability selection.
Future work will extend this analysis to open-source models and explore the stability of personality traits across model versions and fine-tuning approaches.