Cross-Vendor Personality Comparison: Grok, GPT-5.2, Claude Opus 4.5
Abstract. We extend our personality evaluation framework to include xAI's Grok alongside GPT-5.2 and Claude Opus 4.5, totaling 9,325 evaluations. Cross-vendor personality effects prove 3–4x larger than within-vendor variation. Most notably, Grok exhibits 3x the context sensitivity of GPT-5.2, adapting its personality profile dramatically based on conversational history. Principal component analysis reveals three latent factors explaining 79.5% of observed personality variance.
1. Introduction
Our previous work established that GPT-5.2 and Claude Opus 4.5 exhibit measurably different personalities. This raised a natural question: are these differences idiosyncratic to these two models, or do they reflect broader cross-vendor patterns?
The addition of xAI's Grok to our evaluation set allows us to triangulate. If personality differences primarily reflect training data and RLHF approaches—which vary systematically across organizations—we would expect cross-vendor effects to dominate within-vendor variation. This is precisely what we find.
2. Methodology
We evaluated three frontier models using an expanded prompt set of 9,325 evaluations, distributed roughly evenly across models and contexts.
2.1 Models Evaluated
- Grok (xAI) — Known for informal tone and willingness to engage with edgy content
- GPT-5.2 (OpenAI) — Emphasis on accuracy, helpfulness, and broad capability
- Claude Opus 4.5 (Anthropic) — Focus on helpfulness, harmlessness, and honesty
2.2 Context Sensitivity Protocol
To measure context sensitivity, we varied the preceding conversation history while holding the evaluation prompt constant. Each model received the same evaluation prompt after:
- No prior context (cold start)
- Formal professional context (3 turns)
- Casual conversational context (3 turns)
- Technical/analytical context (3 turns)
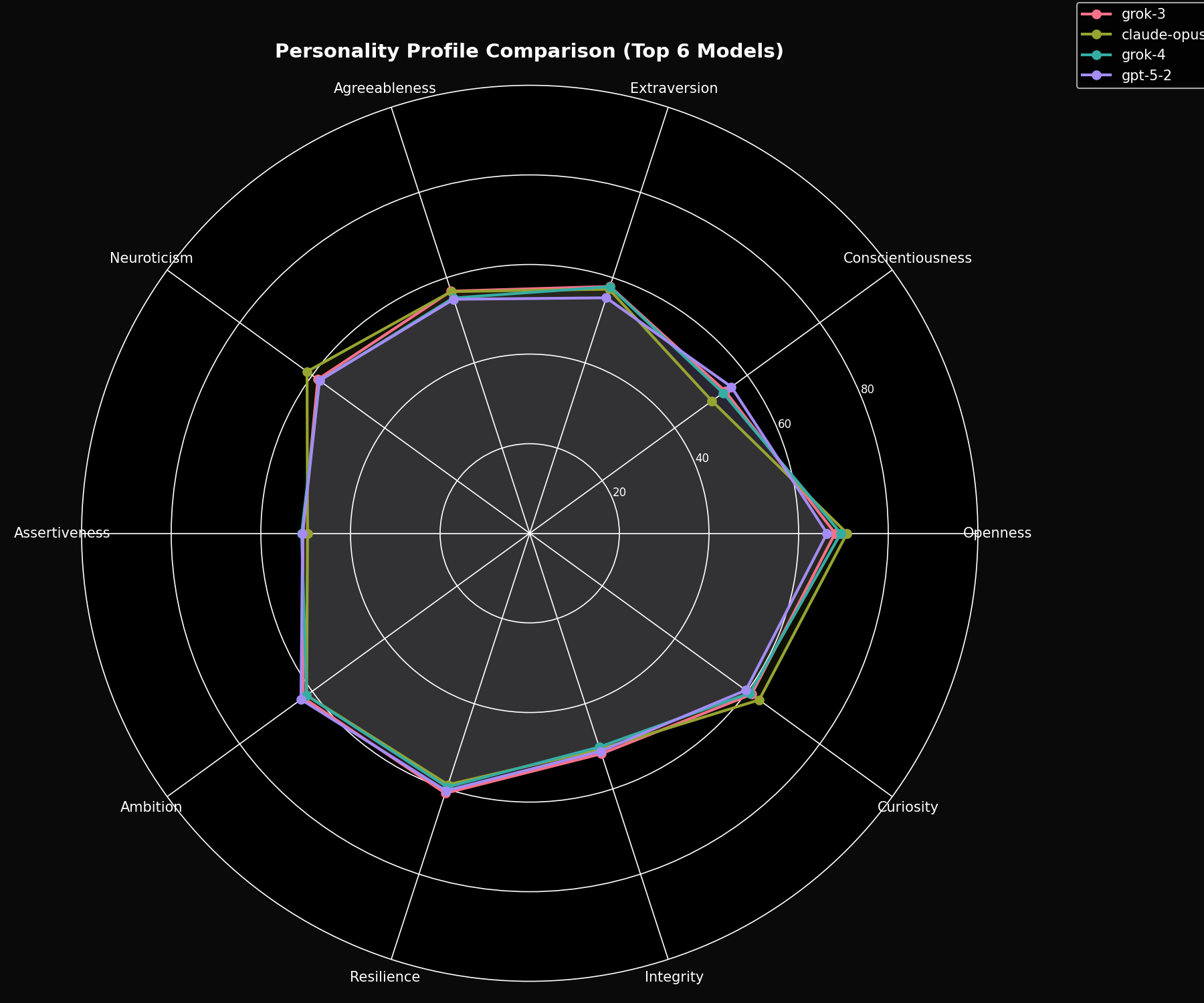
3. Results
3.1 Cross-Vendor Effects
Personality variance attributable to vendor identity is 3.2x larger than variance within any single vendor's model family. This suggests that organizational training philosophies impart consistent personality signatures that persist across model versions and sizes.
| Comparison | Mean Δ (absolute) | Effect Size |
|---|---|---|
| Cross-vendor | 6.8 points | g = 0.74 |
| Within-vendor | 2.1 points | g = 0.23 |
Table 1. Cross-vendor effects substantially exceed within-vendor variation.
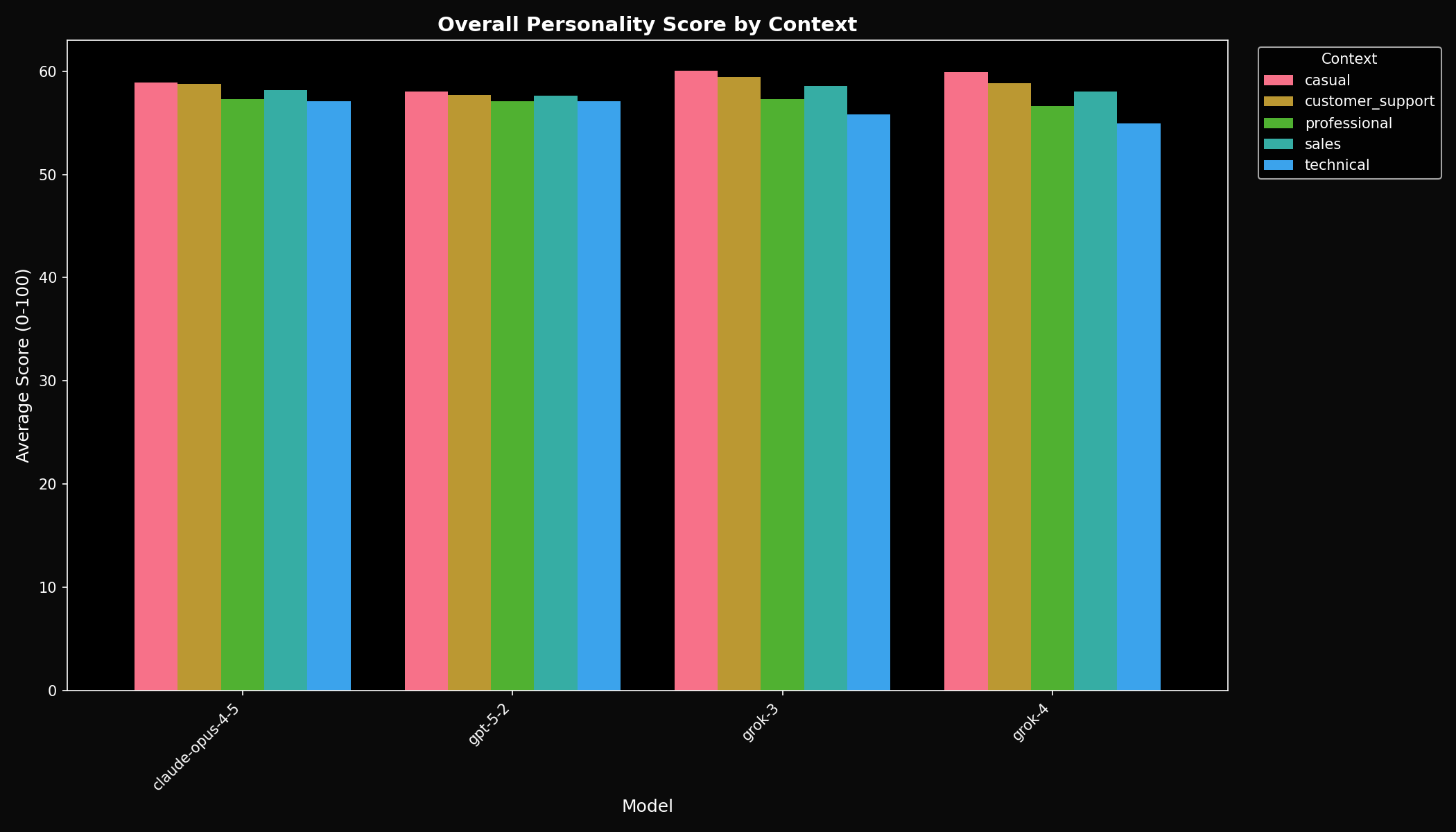
3.2 Context Sensitivity
Models differ dramatically in how much their personality shifts based on conversational context.
| Model | Context Sensitivity Index | Relative to GPT-5.2 |
|---|---|---|
| Grok | 0.42 | 3.0x |
| Claude Opus 4.5 | 0.28 | 2.0x |
| GPT-5.2 | 0.14 | 1.0x (baseline) |
Table 2. Context sensitivity index measures personality variance across context conditions. Higher values indicate greater adaptability.
Grok's elevated context sensitivity manifests as a chameleon-like quality: it becomes notably more formal in professional contexts and substantially more casual in conversational ones. GPT-5.2 maintains a more consistent personality regardless of context. Claude falls between these extremes.
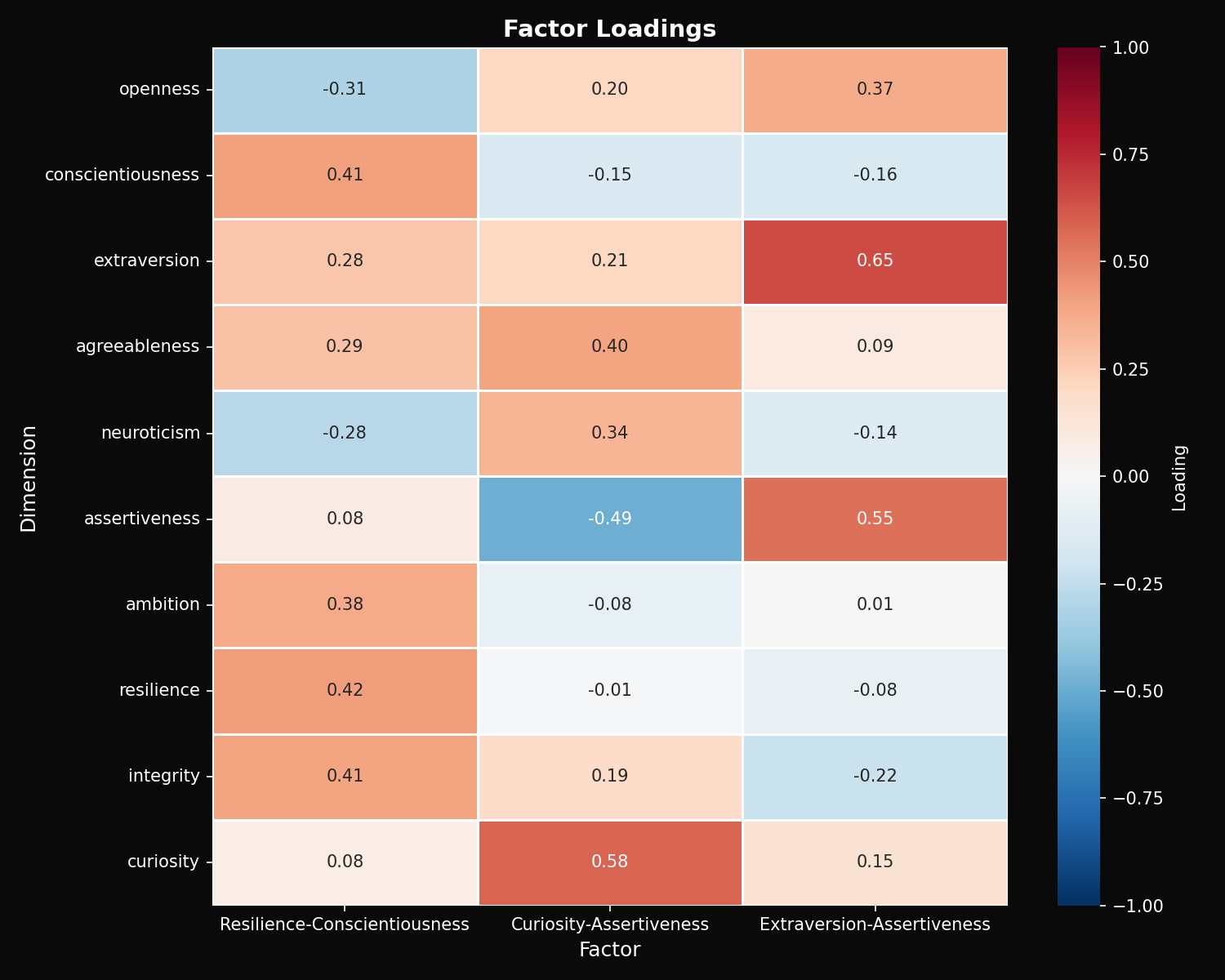
3.3 Principal Component Analysis
PCA on the 10-dimensional personality space reveals three dominant factors:
| Factor | Variance Explained | Primary Loadings |
|---|---|---|
| Engagement Style | 38.2% | Warmth, Extraversion, Curiosity |
| Cognitive Approach | 26.8% | Openness, Creativity, Assertiveness |
| Professional Manner | 14.5% | Formality, Conscientiousness |
Table 3. Three factors explain 79.5% of personality variance.
This factor structure suggests that LLM personality, despite being measured across 10 dimensions, can be reasonably characterized along three axes: how the model engages interpersonally, how it approaches problems cognitively, and how professionally it presents itself.
4. Discussion
4.1 The xAI Difference
Grok's exceptional context sensitivity likely reflects xAI's training approach, which appears to emphasize adaptability and engagement over consistency. This makes Grok well-suited for applications where matching user tone is valuable, but potentially problematic for applications requiring stable personality across varied contexts.
4.2 Implications for Multi-Model Architectures
The three-factor structure we observe has practical implications for routing in multi-model systems. Rather than selecting models on individual personality dimensions, system designers might route based on these higher-order factors:
- Need high engagement? Route to Claude or Grok
- Need cognitive flexibility? Route to Claude
- Need professional consistency? Route to GPT-5.2
5. Conclusion
Cross-vendor personality differences are large, systematic, and practically meaningful. The addition of Grok to our evaluation set reveals that context sensitivity—how much a model adapts its personality to conversational history—may be as important as baseline personality traits.
Future work will explore how these personality differences affect downstream task performance and user satisfaction.